如何从800万数据中快速捞出自己想要的数据?
一、需求调研
正如题目所说,我们使用的是Oracle数据库,数据量在800万左右。我们要完成的事情就是在着800万数据中,通过某些字段进行模糊查询,得到我们所需要的结果集。
这是表里的数据,一共7328976 条数据,接近800万
select count(1) from t_material_new;

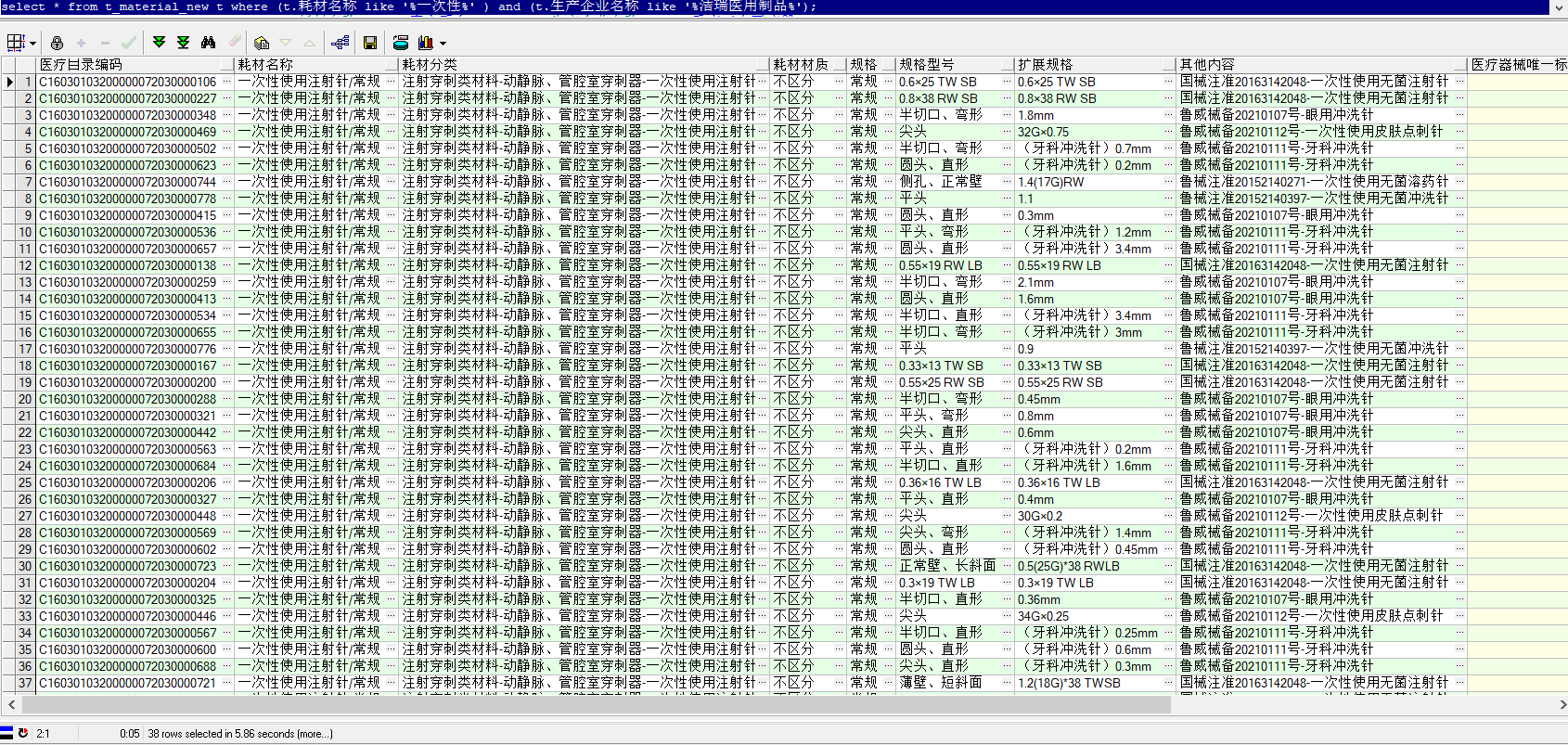
这是我们想要的结果,根据耗材名称、生产企业名称 或其他字段模糊查询出我们想要的结果集
select * from t_material_new t where (t.耗材名称 like '%一次性%' ) and (t.生产企业名称 like '%洁瑞医用制品%');
二、常规思路
一听到要模糊查询,我们想到得关键字当然是like了。
like我们常用的有以下三种匹配方式
- 字段 like '%关键字%' 查询出字段包含”关键字”的记录
- 字段 like '关键字%' 查询出字段以”关键字”开始的记录
- 字段 like '%关键字' 查询出字段以”关键字”结束的记录
我们都知道like关键字的查询效率比较低,我们来看下具体查询效率
1、字段 like '%关键字%' 方式
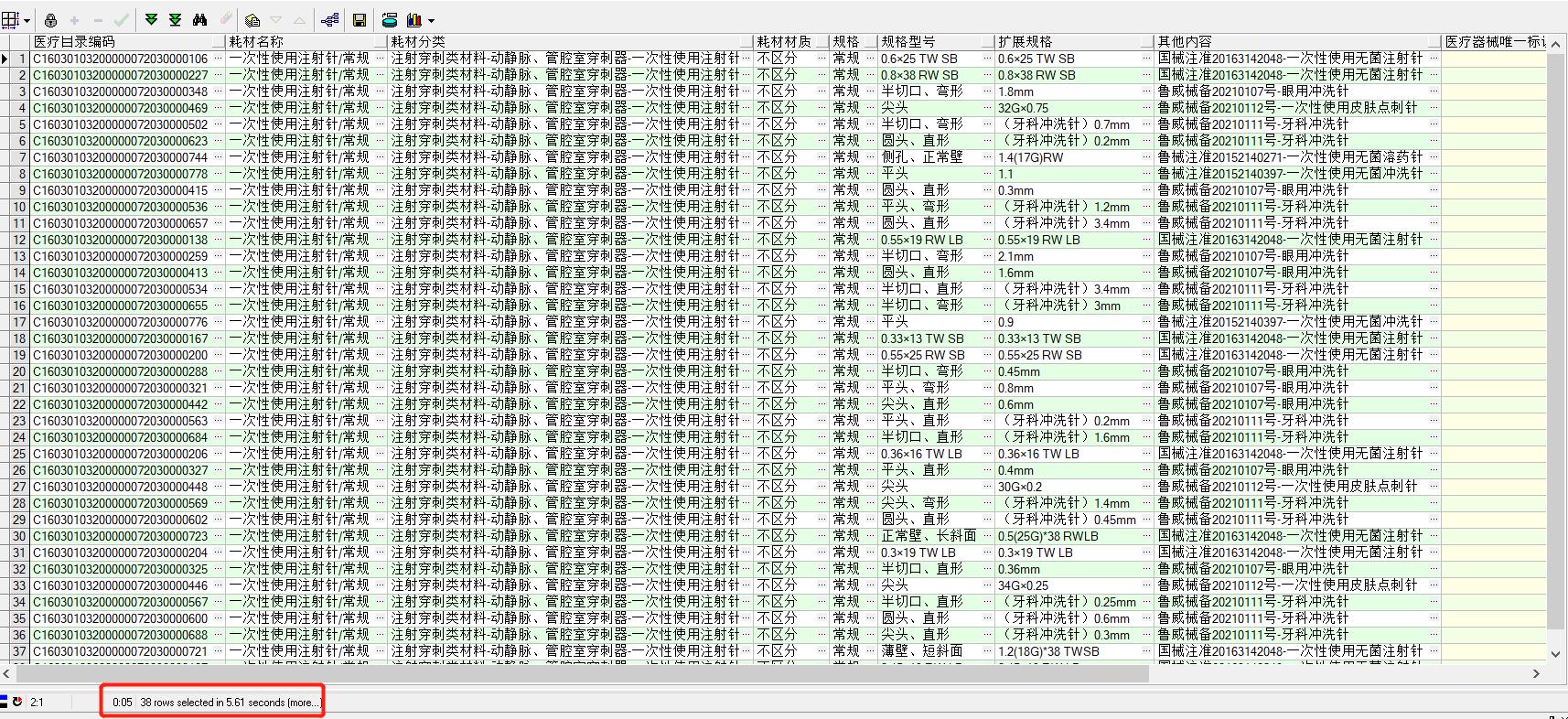
-- 1、查询包含关键字记录 需要花费5.61s
select * from t_material_new t where (t.耗材名称 like '%一次性%' ) and (t.生产企业名称 like '%洁瑞医用制品%');
2、字段 like '关键字%' 方式
-- 2、查询以”关键字”开始的记录 花费0.203s
select * from t_material_new t where (t.耗材名称 like '真空采血%') and (t.生产企业名称 like '重庆三丰医疗器%');

3、 字段 like '%关键字' 方式
3、查询以”关键字”结束的记录 花费0.484s
select * from t_material_new t where (t.耗材名称 like '%肠内') and (t.生产企业名称 like '%疗器械有限公司');

通过以上测试,我们可以得出以下结论
- 字段 like '%关键字%' 没法走索引,效率极低
- 字段 like '关键字%' 和 字段 like '%关键字' 可以走到索引,查询效率可以接受
我们让用户通过第二种、或第三种方式检索也不太现实。
那就只能想想办法看能不能优化了。
四、寻找解决方案
遇到问题总是要解决的,然后就去请教大佬了。
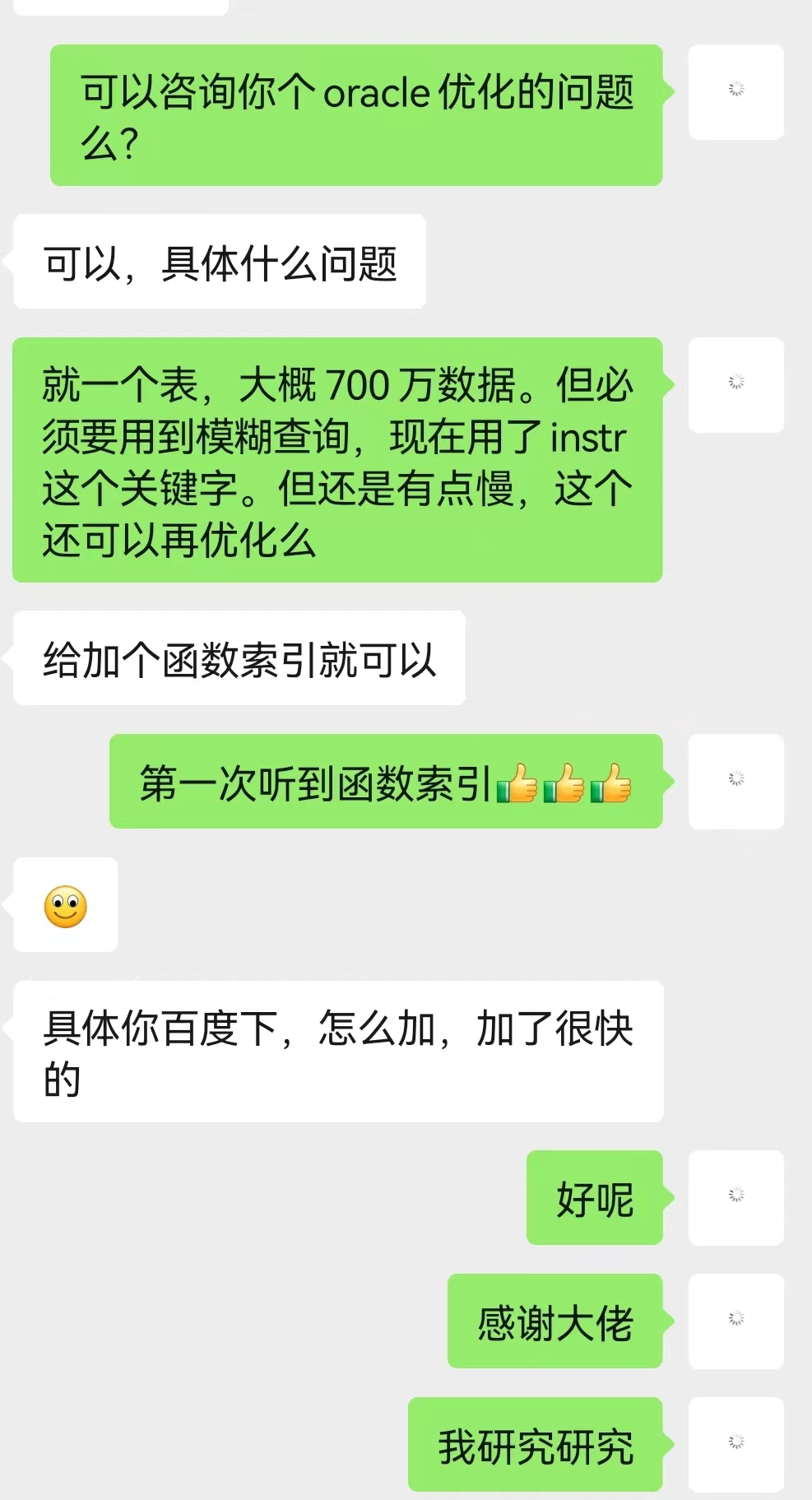
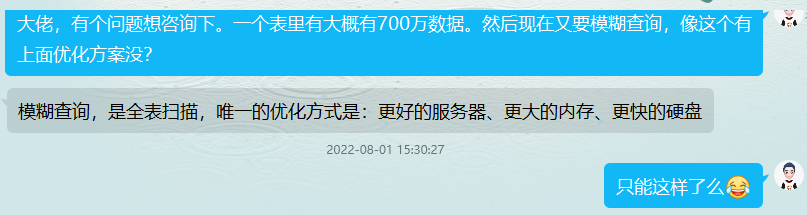
咨询后小结:
(1)建立函数索引
原来函数也是可以建立索引的,get到新技能了。但是这里的由于函数入参内容的不确定性,没法建立函数索引。这种方案便被否决了
(2)提升硬件质量
作为一名资深打工人,提升硬件质量当然不是由我能决定的了。
以上两种方案都不行,那就只能另辟蹊径了。
问了度娘之后,从网上有找到了两种相对靠谱的方案。

1、将like 关键字替换为instr 函数
2、建立全文索引
四、说干就干,实现它
1 将like 改为instr函数
① 函数简介
instr 俗称字符查找函数。用于查找目标字符串在源字符串中出现的位置
② 语法格式
-- sourceString 代表源字符串
-- destString 代表目标字符串
-- start 代表从源字符串查找开始位置,默认为1,可以省略 负数表示倒数第几位开始查找
-- appearPosition 代表想从源字符中查找出第几次出现目标字符串destString 默认为1,可以省略
instr(sourceString,destString,start,appearPosition)
instr('源字符串', '目标字符串' ,'开始位置','第几次出现')
③ 举个栗子
-- 省略后两个默认参数
select instr('helloworld','l') from dual; --返回结果:3 即第一次出现"l"的位置是第3位
select instr('helloworld','wo') from dual; --返回结果:6 即第一次出现"wo"的位置是第6位
select instr('helloworld','wr') from dual; --返回结果:0 即未查找到字符串"wr"
--带上后两位参数
select instr('helloworld','l',2,2) from dual; --返回结果:4 即在"helloworld"的第2位(e)开始,查找第二次出现的"l"的位置是4
select instr('helloworld','l',-2,3) from dual; --返回结果:3 即在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”的位置是3
④ 用instr函数改写上面的sql
select * from t_material_new t where (t.耗材名称 like '%一次性%' ) and (t.生产企业名称 like '%洁瑞医用制品%'); -- 得到结果集需要 6.11秒
-- 相当于
select * from t_material_new t where instr(t.耗材名称,'一次性')>0 and instr(t.生产企业名称, '洁瑞医用制品')>0; -- 得到结果集只需要3.812秒
小结:用instr函数改写like 关键字后,查询效率明显提高了。
但是,还有没有其他方式可以再优化一下呢?
经过小编坚持不懈的问度娘之后,还真找到了另一个方法,那就建立全文索引。
建立全文索引有点复杂,具体操作参照【2使用Oracle全文索引】
2 使用Oracle全文索引
温馨提示:建立索引是需要占用一部分磁盘空间的,这其实也是我们常说的以空间换取时间
① Oracle版本的要求
Oracle 10g或以上版本才支持,其他低版本的就不能使用了
② 建立索引前准备工作
oracle全文检索需要ctxsys用户的支持,我们需要使用ctxsys用户下的ctx_ddl这个包。
在建立全文索引过程中,基本上都在使用这个包。
我们在安装Oracle的时候,ctxsys用户可能没启用。
我们这里要做的有两步
Ⅰ 解锁ctxsys用户,以获得ctx_ddl包的使用权限。
-- 需要以Oracle管理员system用户进行解锁
alter user ctxsys account unlock;
Ⅱ 将ctx_ddl包的操作权限赋给需要操作的用户
grant execute on ctx_ddl to testuser;
③创建分析器
oracle text的分析器 ,类似于lucene中的分词器,将需要检索的记录,按照一定的方式进行词组拆分,然后存放在索引表中。检索的时候根据索引表中存放的拆分词组,对传入的关键字进行匹配,并返回匹配结果集。
oracle text中的分析器有3种:
- basic_lexer:只能根据空格和标点来进行拆分。比如“云南楚雄”,只能拆分为“云南楚雄”一个词组
- chinese_vgram_lexer:专门的汉语分析器,按字单元进行拆分,比如“云南楚雄”,可以拆分为“云”、“云南“、”南楚”、“楚雄”、“雄”五个词组。这种方式的好处是能够将所有有可能的词组全部保存进索引表,使得数据不会遗漏。
- chinese_lexer:一种新的汉语分析器,能够认识大部分常用的汉语词汇,并按常用词汇进行拆分存储。比如“云南楚雄”,只会被拆分为“云南”、“楚雄”两个词组。
为了是的需要检索的数据不会出现遗漏,这里我们选择chinese_vgram_lexer 这个分词器
登录我们需要查询数据的用户,以chinese_vgram_lexer 这种分词器方式创建分析器
-- 创建一个“chinese_vgram_lexer”分析器,名称为my_lexer
begin
ctx_ddl.create_preference ('my_lexer', 'chinese_vgram_lexer');
end;
④ 创建过滤词组
我们在检索数据的时候,通常不需要某些词组进行检索,就如同上面查询条件中的生产企业。
我们不希望输入“公司” 、“有限公司”、“有限责任公司”等这样的关键词,也会检索出结果。
我们就可以通过建立过滤词组,以实现创建索引的时候将这些词组过滤掉
-- 创建一个词组过滤器
begin
ctx_ddl.create_stoplist('my_stoplist');
end;
-- 往词组过滤器中添加过滤关键字
begin
ctx_ddl.add_stopword('my_stoplist','公司');
ctx_ddl.add_stopword('my_stoplist','股份有限公司');
ctx_ddl.add_stopword('my_stoplist','有限责任公司');
end;
⑤ 到了最重要的一步,建立索引
以上所有都是为这一步准备的。
根据需求,我们需要对表t_material_new 中的耗材名称和生产企业名称进行检索。
所以我们需要以耗材名称和生产企业名称字段建立索引。建立脚本如下
注:以下脚本在执行的时候需要花费一点时间,耐心等待即可
-- 在t_material_new表中的【耗材名称】和【生产企业名称】字段上创建索引,索引类系那个为context类型,该索引用到的分析器为前面定义的my_lexer,该索引用到的过滤词组为前面定义得my_stoplist
create index INDEX_MATERIAL_NAME on t_material_new(耗材名称) indextype is CTXSYS.CONTEXT parameters('lexer my_lexer stoplist my_stoplist');
create index INDEX_MATERIAL_PROD on t_material_new(生产企业名称) indextype is CTXSYS.CONTEXT parameters('lexer my_lexer stoplist my_stoplist');
创建完索引后,我们会发现当前用户下,关于INDEX_MATERIAL_NAME 索引多了四个表,关于
INDEX_MATERIAL_PROD 也多了四个表。
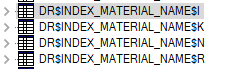

其中t_material_new表中【耗材名称】字段被拆分后的词组保存在dr\(index_material_name\)i表中
其中t_material_new表中【生产企业名称】字段被拆分后的词组保存在dr\(index_material_prod\)i表中
我们来查询下表的具体内容看看
select * from dr$index_material_name$i;

select * from dr$index_material_prod$i;

⑥ 如何使用索引?
-- 将以上查询sql改下为用全文索引的查询方式 (查询出我们想要的结果集仅仅需要0.312秒)
select * from t_material_new t where contains(t.耗材名称,'一次性')>0 and contains(t.生产企业名称, '洁瑞医用制品')>0;
到此,基本上已经圆满完成了我们的需求任务。
我们做到了模糊查询从 6.11秒--> 3.812秒--> 0.312秒
可能细心的小伙伴会发现一个问题,
如果表t_material_new 中插入了新的数据,那么分析器中不就没记录到这些词了吗?
小伙伴提的这个问题挺好的,当然我们也有对应的方法解决
⑦ 完善我们的索引
当我们需要修改t_material_new 表中的数据,比如添加、删除、更新等操作时,INDEX_MATERIAL_NAME和INDEX_MATERIAL_PROD索引是不会同步更新数据的,需要我们在程序中手动的更新。
-- 更新同步索引中分词数据
begin
ctx_ddl.sync_index('INDEX_MATERIAL_NAME')
ctx_ddl.sync_index('INDEX_MATERIAL_PROD')
end
当然了我们可以在表t_material_new 上写一个oracle的触发器,当添加、删除、修改操作时,进行索引分词更新;或者创建定时任务定时更新也可以。
定时任务的建立可以参照之前写过的文章
Oralce定时任务实际应用
到此,Oracle模糊查询优化就算完成了,但是还想分享一个小技巧。
怎么将excel 表格中的数据快速导入到Oracle数据库中呢?
要是数据少,都好说。当数据量到几十万、或者几百万的时候就比较难了。
这里推荐用Navicat工具导入
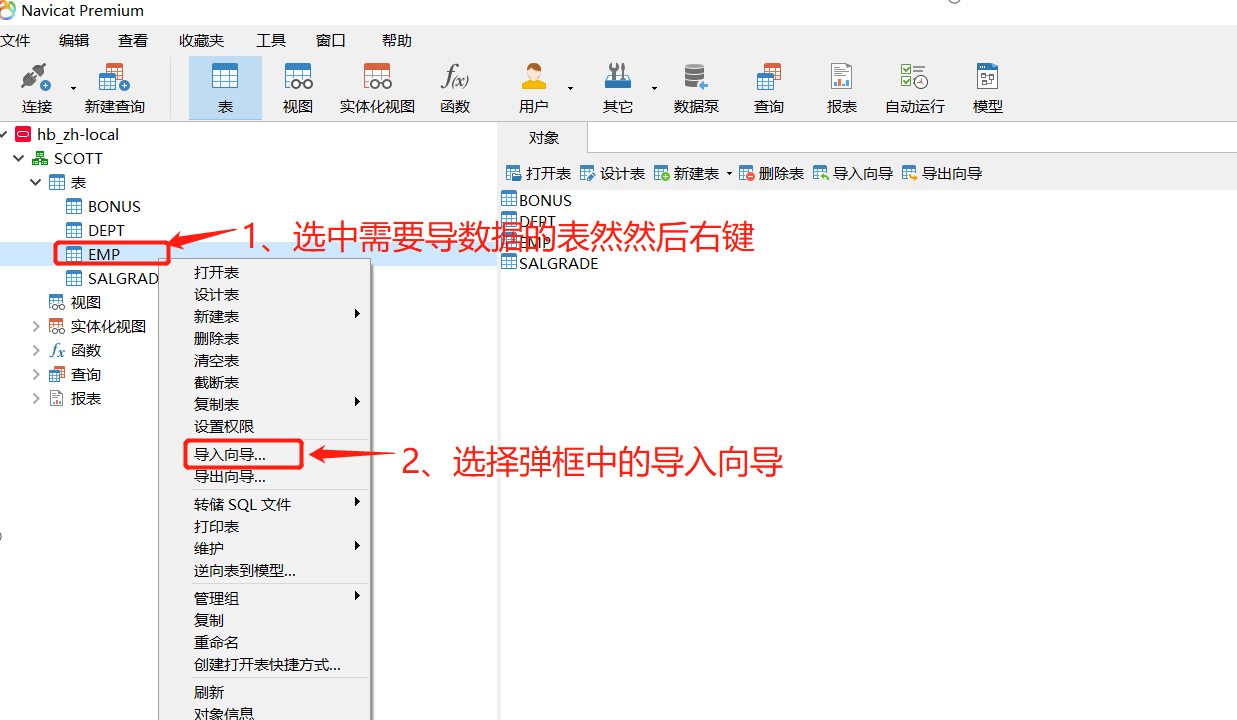
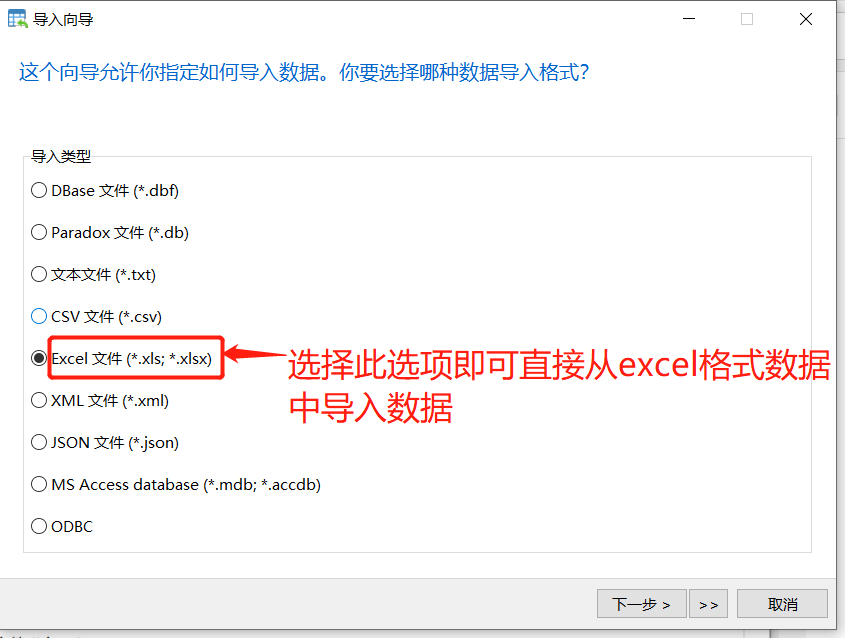
个人亲自实测,导入速度还是挺快的。
以上就是文章的全部内容了,希望对你有所帮助
热门相关:无量真仙 名门天后:重生国民千金 夫人,你马甲又掉了! 战神 横行霸道